TL;DR
- Restructured Cotality's flat per-seat pricing to value-based tiers, delivering material ARR growth across thousands of active enterprise seats
- Built metered AI billing at OpenChair and OpenTradie using Stripe, with multi-model orchestration achieving 90% inference cost reduction through prompt caching and model routing
- AI pricing requires understanding architecture: you cannot set a price per AI action without knowing the inference cost, and inference cost varies by model, prompt length and caching strategy
The Problem
At Cotality, the pricing model was flat per-seat. Every user paid the same regardless of which products they accessed, how frequently they used the platform, or which features generated the most value. For a portfolio serving real estate agents, mortgage brokers, valuers and banking analysts with vastly different usage patterns, this was leaving money on the table and misaligning incentives.
At OpenChair and OpenTradie, the problem was different but related. AI features (voice receptionist, smart scheduling, growth coaching, vision-based recommendations) each have different inference costs depending on the model used, prompt complexity and response length. A feature that costs $0.15 per inference and gets used 50 times per user per month consumes $7.50 per user per month in inference alone. If the user pays $30 per month, that's 25% of revenue consumed by a single feature. Without the cost model, this math only becomes visible after launch.
The Approach
Two different contexts required two different pricing architectures, but the same underlying discipline: understand the unit economics first, then design the pricing model around them. I expand on this in the AI pricing stack framework and the broader business viability handbook.
At Cotality, this meant analysing usage patterns across segments (agents vs. brokers vs. valuers vs. banking analysts), identifying which features drove the most value for each segment, and restructuring into tiers that aligned price with value delivered.
At OpenChair and OpenTradie, it meant mapping every AI feature to its inference cost profile, routing tasks to the most cost-effective model that met quality requirements, and building metered billing infrastructure that tracked and charged for AI usage at the action level.
Key Decisions
1. Value-Based Tiers at Cotality
The flat per-seat model treated all users as identical. They weren't. I write about why per-seat pricing breaks down in the agentic era more broadly, but at Cotality the symptoms were already visible: a real estate agent accessing property reports weekly derives different value from a banking analyst running portfolio risk assessments daily. The tiered structure segmented by feature access and usage intensity, creating packages where each tier unlocked progressively more capable tooling.
The restructure delivered material ARR growth without increasing churn. Clients who were overpaying for features they didn't use moved to appropriate tiers, reducing their friction with the platform. Clients who were underserving their teams upgraded to access features that matched their actual workflows.
2. Investment Case Framework for GenAI Features
Before any AI feature was approved for development at Cotality, it required an investment case covering four dimensions: inference cost per request (based on model, prompt design and expected token volume), expected usage volume (requests per user per month), pricing impact (how the feature would be monetised or justify tier placement), and margin analysis (the gap between cost-to-serve and revenue attributable to the feature).
This framework prevented the common enterprise mistake of shipping AI features that impress in demos but destroy margin at scale, a failure mode I dissect in the AI copilot margin trap. Without the investment case, the math only becomes visible after launch, when it's too late to change the architecture.
3. Multi-Model Routing as Cost Management
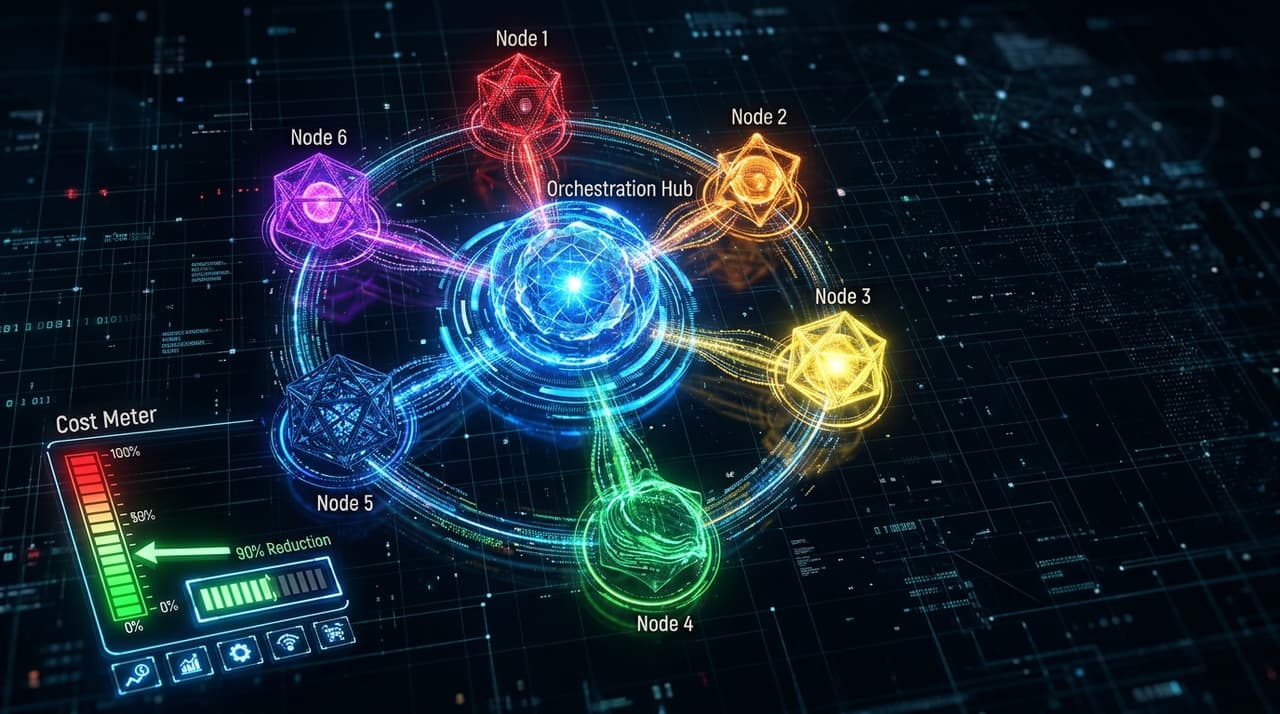
At OpenChair and OpenTradie, I route tasks across six LLMs via OpenRouter based on the cost-quality-latency profile of each task. Claude Sonnet handles quality-critical generation (client-facing recommendations, business analysis). Claude Haiku processes classification, extraction and high-volume background tasks. GPT-4o Mini handles cost-sensitive operations where quality requirements are lower. Gemini serves specific multimodal tasks.
This routing isn't just an architecture choice. It's a pricing decision. The difference between sending every request to Claude Sonnet versus routing appropriately is the difference between a profitable AI feature and a margin trap. I cover the full technical architecture in the multi-model orchestration case study and the conceptual framework in the multi-model orchestration handbook. Combined with prompt caching (which eliminates redundant processing of system prompts and repeated context), the orchestration layer achieves 90% cost reduction compared to a single-model approach.

4. Metered Billing via Stripe
OpenChair and OpenTradie use Stripe's metered billing to charge for AI features at the action level. Each AI action (voice call handled, recommendation generated, growth insight produced) is tracked, costed and billed. Venue operators see exactly what they're paying for and can control costs by adjusting which AI features they enable.
This solves the cannibalisation paradox. When AI features reduce the number of human actions (and therefore seats) needed, per-seat pricing penalises your own product's success. Metered billing ties revenue to value delivered, not headcount. If the AI receptionist handles 200 calls per month at OpenChair, the venue pays for 200 calls handled, regardless of whether they employ one receptionist or zero.
5. Architecture Informs Pricing, Pricing Constrains Architecture
The most important lesson spanning both contexts is that pricing and architecture decisions are circular. At Cotality, the pricing restructure required understanding which features drove value (an architecture and usage question) before setting tier boundaries. At OpenChair and OpenTradie, the multi-model routing architecture exists partly because a single-model approach would make metered billing unprofitable at target price points.
If your pricing team and your architecture team don't talk to each other, your AI products will either be too expensive for customers or too expensive for you.
Results
- Cotality tiered pricing: material ARR growth across thousands of active enterprise seats
- Churn reduced by more than 30% (pricing alignment reduced friction and underutilisation)
- GenAI investment case framework adopted for all AI feature development
- OpenChair/OpenTradie: metered AI billing operational in production via Stripe
- Multi-model orchestration: 90% inference cost reduction through routing and prompt caching
- Zero margin-negative AI features shipped (every AI feature covers its inference cost at target usage)
Tech Stack
Cotality: Tiered pricing architecture, usage analytics, enterprise account management, AFSL-regulated pricing governance
OpenChair/OpenTradie: Stripe Billing (metered), OpenRouter (multi-model routing), prompt caching, Langfuse (cost monitoring per feature), six LLMs (Claude Sonnet, Claude Haiku, GPT-4o Mini, Gemini 2.0 Flash, Gemini 2.5 Pro, Gemini 2.5 Flash)